DevOps nos permite entregar valor al negocio de un modo sostenido, obteniendo feedback de producción de un modo temprano, de modo que nuestras decisiones sean tomadas en base a datos objetivos.
Entregar features rápido no implica que todas estas features resulten siempre satisfactorias para nuestros usuarios o el negocio. Algunas pueden fallar (tener bugs) o pese a funcionar correctamente, no resultar útiles o cómodas a nuestros usuarios, generando rechazo.
En esos casos, una exposición progresiva (Progressive exposure) de estas nuevas features puede reducir el rechazo, o al menos que este se produzca en un número reducido de usuarios, en vez de en toda nuestra base de clientes.
El conjunto de usuarios a los que llega una nueva feature se conoce como Radius blast, por analogía con el radio de expansión de una bomba. Si decimos que incrementamos el Radius blast, estaremos haciendo que una feature llegue a más usuarios.
Feature flags y Deployment rings
Dos de las técnicas más extendidas que podemos usar para exponer nuestras features progresivamete a nuestros usuarios son el uso de feature flags y la estrategia de despligue en anillos (deployment rings).
Ambas cumplen el propósito, pero como no podía ser de otro modo, presentan pros y contras, que debemos conocer antes de "lanzarnos" a seleccionar una.
Deployment rings
Fueron descritos por primera vez por Jez Humble en el famosísimo libro "Continuous Delivery", donde se hablaba también de canary deployments, que podemos considerar un caso especial de despliegue en anillos.

Se trata de disponer de varios entornos de producción, siendo cada uno de tus usuarios siempre enrutado al mismo entorno, por criterios variados (geográficos, por tipo de usuario, por antigüedad u otros).
Cuando se despliega una nueva feature, inicialmente solo estará disponible en el primero de los entornos (anillo), donde será visible solo para un porcentaje de usuarios (los redirigidos allí).
A partir de ese momento comenzaremos a monitorizar activamente el comportamiento de esta nueva feature en ese primer anillo, para pasado un tiempo razonable, decidir si la progresamos al siguiente anillo (hemos ganado suficiente confianza) o bien es necesario algún cambio en el software, y por tanto un nuevo despliegue al primer anillo.
Este mismo proceso lo realizaremos para cada uno de los anillos que hayamos definido. Podemos verlo en el siguiente gráfico:
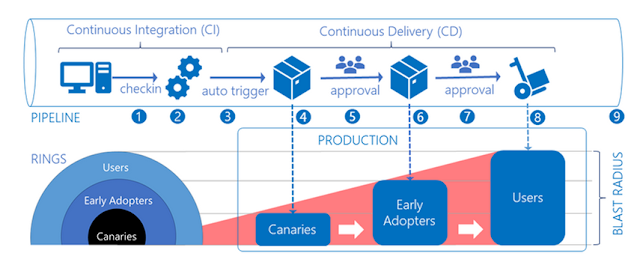
Como veis se han definido 3 anillos: al primero lo llaman "Canaries", el siguiente es para "Early adopters" y el último engloba al resto de usuarios. A modo de ejemplo, y para una aplicación tipo "Spotify" podríamos definirlos así:
- Canaries: trabajadores de Spotify
- Early adopters: Clientes que han indicado que quieren recibir versiones "beta"
- Users: resto de usuarios
Podríamos definirlo de otro modo, con más o menos anillos y usando otros criterios como decía antes, pero lo importante es el proceso, que paso a detallar:
- Un commit llega a la rama principal
- Se dispara atomáticamente el pipeline de CI/CD
- Se compila, se pasan los tests y se empaqueta el software
- Se despliega en el primer anillo
- Se monitoriza activamente durante un tiempo definido
- Si se encuentra algun problema, se descarta la release y no será progresada a siguientes anillos
- Si no se encuentran problemas, se progresa la release al siguiente anillo. Podría ser con una acción de aprobación manual o de modo automático (cuando termina el tiempo definido)
- Se actúa igual en los siguientes anillos
Como vemos ganamos en confianza a coste de ser más lentos haciendo llegar las nuevas features a nuestros usuarios.
¿Qué herramientas podemos usar para implementar una
estrategia de despliegue en anillos?
Sin duda mis favoritas son GitHub actions y Azure Pipelines, aunque podríamos usar otras como CircleCI, Jenkins o GitLab
En GitHub actions nos será muy útil usar environments (aunque solo están presentes en la versión Enterprise):
En Azure DevOps Pipelines, también nos apoyaremos en los environments, y además disponemos de las Gates, que nos pueden ayudar a monitorizar nuestra release en un anillo para decidir si progresa al siguiente:
https://docs.microsoft.com/en-us/azure/devops/pipelines/release/approvals/
Feature flags (o feature toggles)
Fueron descritos por primera vez por Martin Fowler en este artículo y nos permiten desacoplar la exposición progresiva de features del despliegue de una release. Para ello, las nuevas features van controladas con un toggle, que nos permite, en tiempo de ejecución, elegir si se encuentran activas o no, y por tanto modificar el comportamiento de nuestro software.

Es decir, podemos desplegar una release con varias features desactivadas, para más adelante activarlas poco a poco, monitorizando en todo momento su comportamiento.
¿Qué necesitamos para esto?
- Un servicio de gestión de toggles.
- Una query que pregunte en tiempo de ejecución el valor de un toggle
- Una remificación if-else (o algo más sofisticado) en nuestro código que haga que el software se comporte de distinta manera cuando el toggle esté o no activado.
¿Qué herramientas podemos usar?
Azure App Configuration nos ofrece una gestión simple de Feature
toggles, que puede servir en algunos escenarios, pero lo más seguro es que
rápidamente necesites algo más avanzado, como Xabaril Esquio (un paquete para .NET hecho por
algunos amigos) o un servicio como LaunchDarkly.
¿Qué opción elegir?
Como siempre que se hacen este tipo de preguntas, sería temerario responder categóricamente, un "depende" siempre es más acertado.
En ambos casos vamos a controlar qué usuarios reciben features, para después ir exponiéndolas progresivamente a otros grupos de usuarios o la totalidad de estos. Además ambas opciones nos van a permitir realizar un A/B testing controlado.
No obstante hay algunas diferencias importantes que debemos conocer.
Coste
Con Deployment rings vamos a necesitar varios entornos de producción, mientras que con Feature flags vamos a necesitar una herramienta para controlarlas (con un store para persistir las toggles), además de cambios en nuestro código para gestionarlas.
Para mí este último detalle es importante. Mantener muchas toggles no es gratis, tu código se ve afectado, y las toggles deben ser eliminadas una vez que hemos decidido que una feature nunca más será desactivada.
La deuda de toggles puede ser peligrosa, y debemos tener en cuenta que no se trata solo de borrar la toggle, sino la ramificación de código asociada. Por aquí hablan de ello: https://codescene.com/blog/feature-toggles-are-technical-debt/
Gestión del Radius Blast
Podemos pensar que es más sencilla con los Deployment rings, ya que se trata de enrutar a los usuarios al entorno adecuado según los hayamos categorizado (canaries, early adopter o usuario general en el ejemplo que presentaba).
Sin embargo las librerías y los servicios avanzados nos permiten definir grupos de usuarios y conseguir efectos similares con toggles.
Además las Feature toggles nos "regalan" un rollback sencillo: si una feature no funciona podemos desactivarla al momento.
Confianza
La confianza es algo importante para mi, siempre digo que quiero dormir por las noches. Con Feature toggles, lo normal es que tengas un único entorno productivo, por lo que cuando despliegas una release, esta va a todos los usuarios, aunque para algunos haya features desactivadas.
Si una release es "mala", a veces eso pasa :-(, y su problema no está tras una feature toggle, todos los usuarios lo sufrirán.
Sin embargo, con Deployment rings, solo los usuarios del primer anillo "sufrirían" esa "mala" release.
Habilidades del equipo y aspectos organizativos
Diría que
la opción de las Feature toggles es más cercana al desarrollo, mientras que los Deployment rings están más cerca de la infraestructura. Las habilidades de tu equipo o la
organización de tu empresa pueden determinar la decisión.
¿Podemos usar ámbas opciones simultaneamente?
Claro, y
en algunos casos será la opción más acertada :-)
Continuaré con estos temas en otros posts, espero que sean de interés.
Actualización:
Me indica Vicenç García que en Uber han hecho su propia herramienta para manejar esa deuda asociada a las Feature flags. ¡Gracias!
Introducing Piranha: An Open Source Tool to Automatically Delete Stale Code - Uber Engineering Blog





















